

Inside the race to power AI take-off
Projecting AI chip supply, compute demand, and its implications


As discussed here and here, humans have so far provided the 'intelligent compute' for our advanced industrial civilisation. But as this is augmented with new forms of AI, it is clear that the new contributions are dependent on a combination of brute-force processing and high-quality input data.
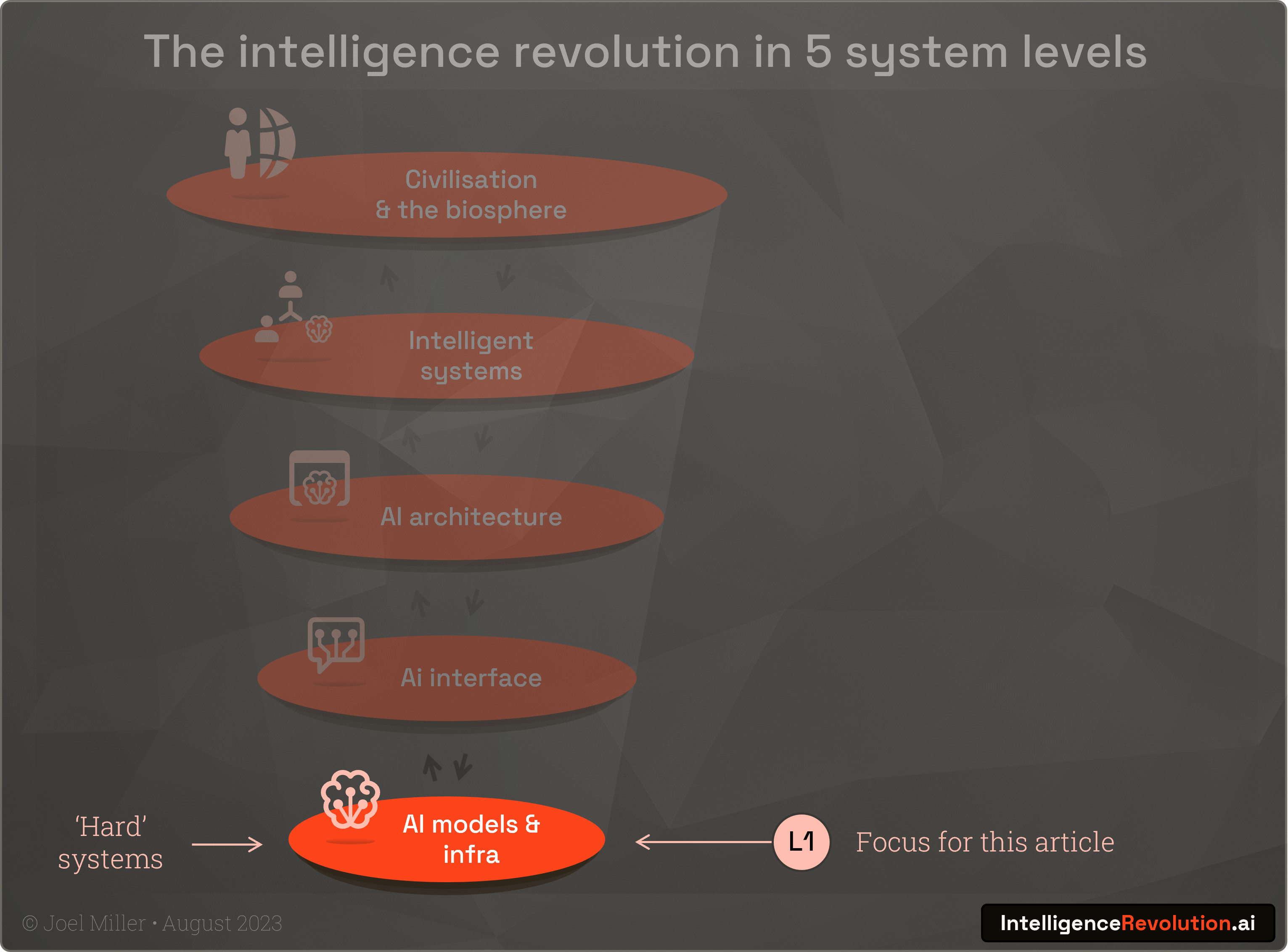
In this article I explore the hard systems and hard numbers at the foundation of the intelligence revolution and assess the constraints that will shape the dynamics of change in the next 3 years. I explore level 1 (of a 5 level systems view of the intelligence revolution) and specifically the current computational infrastructure:
Humans are unique amongst primates in the time we take to reach adulthood, and research suggests that mammalian brain power, or number of cortical neurones, determines lifespan and time spent 'training'. So, it could be theorised that biological intelligence is a product of brain scale and the ingestion levels of high-quality experiences and data.
Intelligence = compute x data
We can visualise this on a simple 2-axis chart, with relative positions of our older 'narrow' AI, and the lofty position of humans. Our latest generation of neuromorphic AIs such as ChatGPT whilst not yet able to process the huge volumes of data from the entire Internet in the way a search engine can, have scaled up to ingest much more training data than a single human does in a lifetime. AI has moved materially on this chart in relation to human intelligence in the last few years:
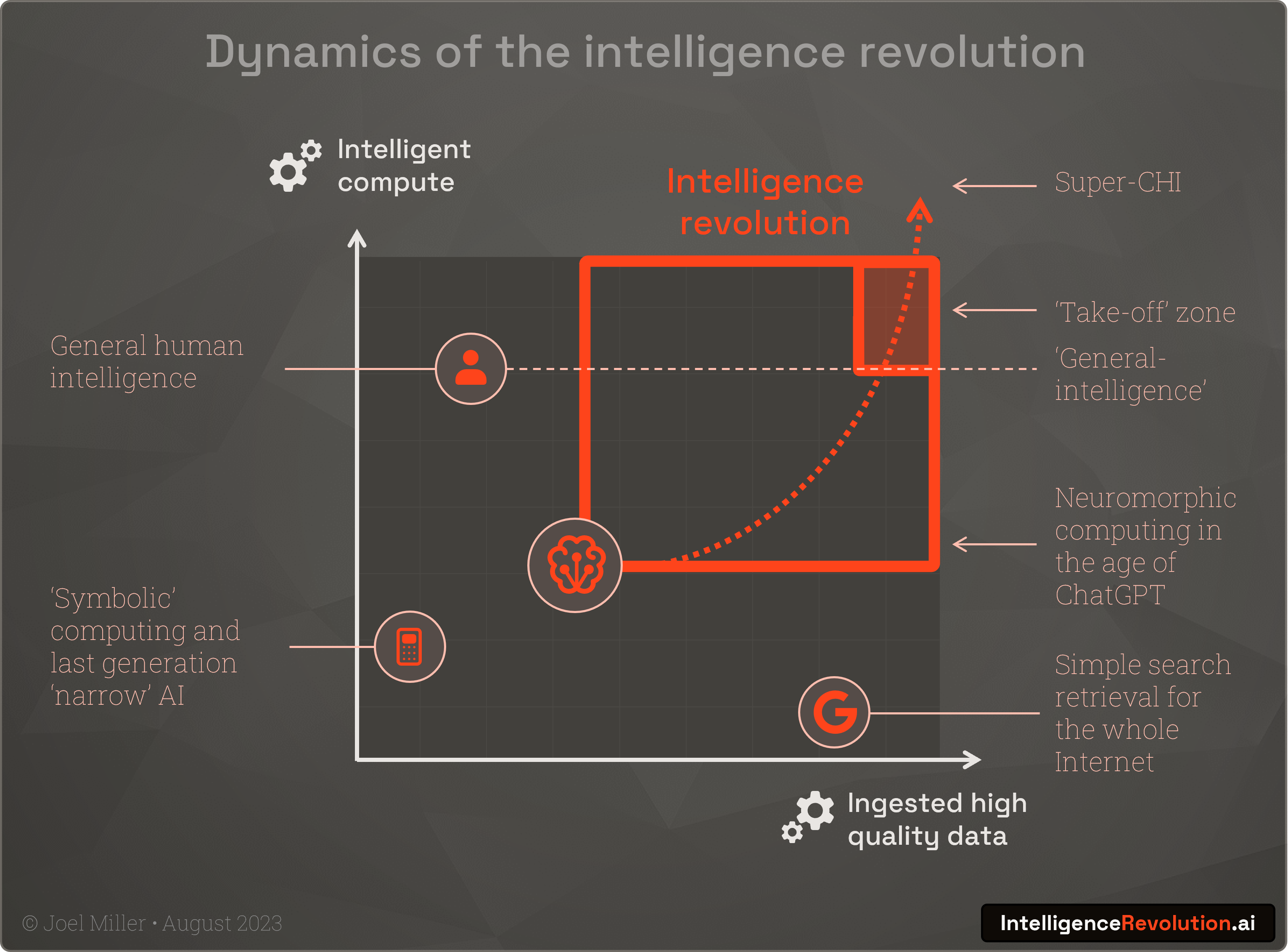
To understand how rapidly the intelligence revolution will happen from this point, we must understand how compute and data are accelerating or limiting progress. Some people talk of a 'token crisis' and it’s true that OpenAI may struggle to gather more than the 13trn text tokens of sufficient quality for future training runs. But as they have moved to using images, where a picture may be worth a thousand tokens, there is also the promise of AI generated training data and many reserves of high-quality data in the corporate and academic worlds. To put this in perspective, GPT-4's ~100TB training dataset pales in comparison to the 'size of the Internet', which is forecast to grow to some 175,000,000,000TB by 2025. In the near-term it will be much harder to innovate through the physical limits of AI chip availability, and it’s safe to state that right now we're experiencing a 'compute crunch'.
A seminal essay by the AI expert Rich Sutton describes the “the bitter lesson” of AI research; efforts to add human nuance to models is always ultimately beaten by brute-force computation:
"The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin."
Rich Sutton
What the essay also highlights, which is born out be recent progress, is that generalised methods that maximise the use of compute are the game-changers; exactly as has been achieved by the advent of the transformer model and its ability to run very performantly on highly parallel GPU architectures originally designed for 3D gaming.
Semi-conductor manufactures assemble!
At the core of intelligent hybrid human-machine systems is the semi-conductor industry and the development of powerful GPUs with thousands of processing cores optimised for massively parallel matrix calculations. A combination of new algorithms plus growing GPU power that has continued an adherence to Moore's law (in the case of high-end GPUs, with FLOPs/$, doubling every 2.07 years) has enabled a revolution, but is also now holding it back. The Jevons paradox is in full force in that the increase efficiency in computation is driving new levels of demand:
AI chip availability is the talk of Silicon Valley and GPUs are the hottest commodity on earth. The harsh reality is AI today is limited by the tiniest fraction of the world's chips (~0.00005%), available only in the highest bandwidth, and most power-hungry datacentres.
"We’re so short on GPUs, the less people that use the tool, the better."
Sam Altman, CEO OpenAI
A constrained system of supply
AI chips designed by Nvidia, Google, AMD, Intel, and a small number of other firms are produced in a highly concentrated supply chain that relies on a tiny band of suppliers and manufacturers. Today a single fabricator, TSMC in Taiwan, makes Nvidia's and Google's AI chips relying in-turn on a single supplier of EUV lithographic production technology, ASML. These chips are assembled into servers by a small number of OEMs and today the demand for these machines from the hyperscalers such as Microsoft, Amazon and Google, plus private clouds and national high performance computing centres is exploding.
We can visualise the supply system for AI chips as follows with several key bottlenecks labelled A-E:

A. Fabrication & packaging
As mentioned, a single firm, TSMC, is responsible for the vast majority of current AI chip production using advanced sub-5nm production processes. Whilst other firms can produce high-end chips, those from firms other than Nvidia or Google are not widely used for AI training and inference due to a lack of preferred development tools. Additionally, models run most efficiently for inference on the same architectures used to train, which further limits options. The intelligence revolution today is primarily limited by the number of chips TSMC can produce and its fabrication and packaging capacity.
As the world’s largest manufacturer, with 54% of the market, TSMC manufactures for all other AI players including AMD and Intel. Whilst wafer supplies are currently healthy, capacity is often initially constrained by the demands from other larger non-AI customers, such as when consumer firms launch a big new product. For example, 100% of TSMCs 3nm capacity will be consumed by Apple for their next generation of iPhones and Macs.
The latest Nvidia 'Hopper' or H100 chips are sizeable pieces of silicon, and if Nvidia are to ramp up to their target of 2m in 2024 they will need command a much increased proportion of TSMCs wafer supply.
In addition, Nvidia's TSMC chips depend on advanced high-bandwidth memory (HBM) from a few suppliers such as SK Hynix, limited supply of silicon interposers, and a CoWoS (Chip-on-Wafer-on-Substrate) packaging process which has additional supply complexities.
Whilst TSMC are ramping up production, the surge in demand is a recent situation and with the investment ($10-20bn per plant) required to build new production facilities, this takes time to expand. TSMC are building new fabs outside Taiwan, including a new sub-5nm facility in Arizona, which will come on stream from the 2025. However, these can be delayed by the availability of local expertise and are not a quick fix.
With a single chip taking 3-6 months to manufacture and above-mentioned factors, AI chip demand is likely to be constrained primarily by TSMC until 2025 at the earliest.
On a more positive note, the move to smaller transistor sizes continues apace, and the angstrom era is around the corner with the likes of TSMC, Intel, Samsung and ASML ready to combine to bring more finer precision fabrication on-stream the next 2-3 years.
B. Distribution & data centres
Microsoft as a major cloud 'hyperscaler' recently used their annual report to highlight AI chip availability and datacentre capacity as a material risk to future revenues. They are competing for supply of the latest H100 chips from Nvidia which offer roughly 6x AI performance over the previous A100s. Nvidia are in a powerful position to decide where to distribute. Whilst the majority are going to Microsoft Azure (and Open AI), Amazon's AWS, and Google's GCP, as these firms are also developing their own competing custom AI chips, Nvidia are prioritising alternatives such as Oracle's cloud and private cloud providers such as Coreweave. Competition is fierce with firms that have obtained chips are likely to hoard them rather than release them to provide compute for competitors. Right now, the frontier labs such as Open AI, big-tech firms from Meta to Apple and even nation states such as UAE and Saudi Arabia are all betting big on AI and want to monopolise computational resources.
Why not use more of the compute we already have? Unfortunately, whilst firms like Coreweave developed their know-how building infra for the crypto boom, mining GPUs and ASICS are not suitable for the memory heavy challenges of LLM training and inference. High-end AI infrastructure is 10-30x more expensive than general purpose hyperscaler kit and requires 4x the power density when installed in a data centre, so new and upgraded data centres will be required. Land and power supplies are severely constrained, and this is like to play a big part in the AI compute crunch in the coming years.
C. Performance, workloads and the memory wall
Assuming the latest AI chips from Nvidia, Google and others start to make it into data centres in volume, the next bottlenecks are performance and workload based, specifically memory limitations and the shear amount of compute required to meet lifetime inference demand.
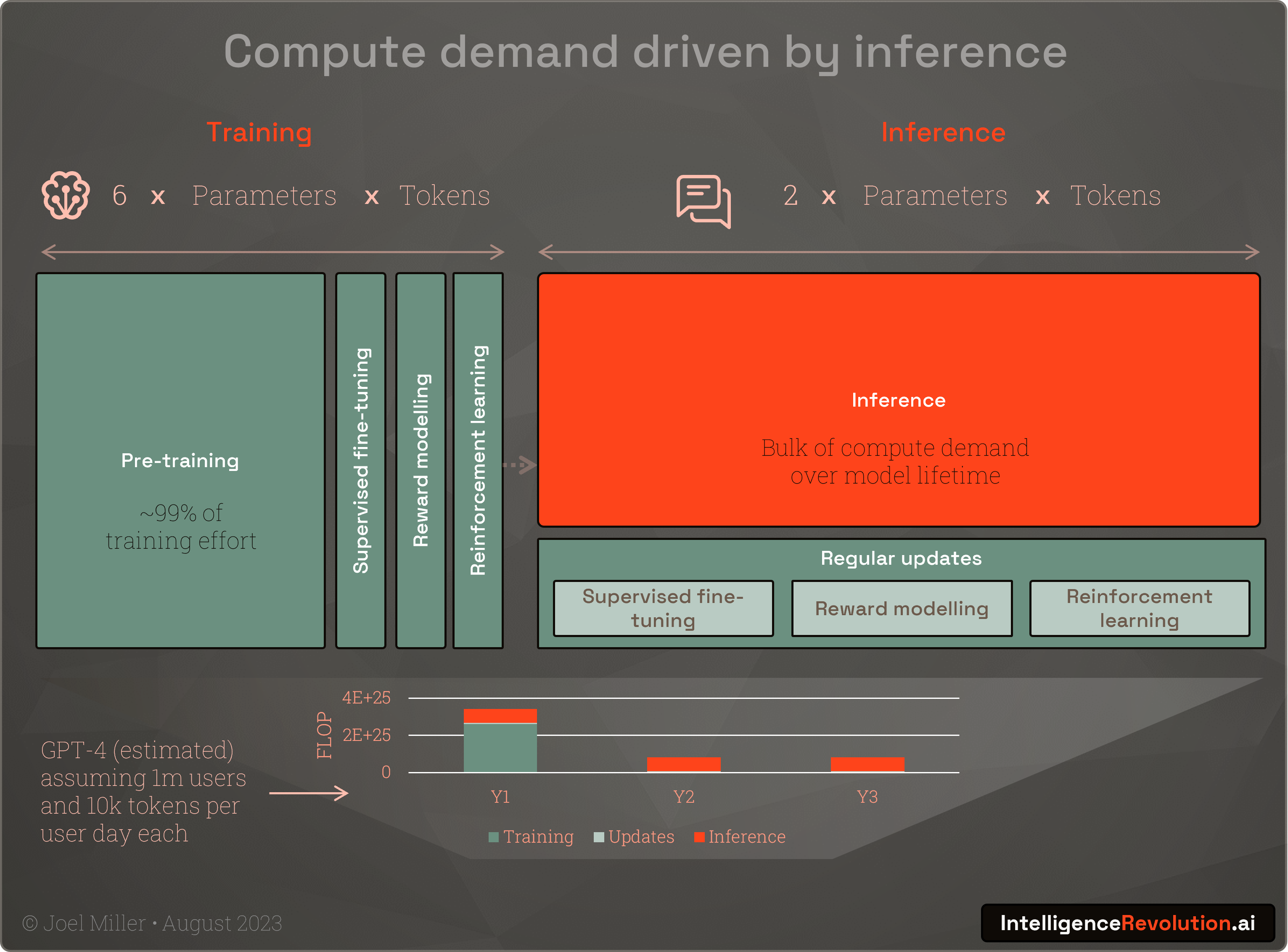
Generating "hello world!" with GPT-4 takes several trillion inference operations. Whilst inferencing is less intensive than training it needs to be low-latency, and 24x7 for the multi-year lifetime of a model, and we’ve only just scratched the surface in terms of usage. Inference is also sensitive to the fact that memory bandwidth is not increasing in-line with FLOP performance and is often overwhelmed by large model sizes.
“Peak hardware FLOPS has increased by 90,000x over the past 20 years, while DRAM/interconnect bandwidth has only scaled by a factor of 30x over the same time period.”
Amir Gholami, Research scientist, UC Berkeley
The H100s running GPT-4 inference today may be much faster but are spending a lot of time waiting for memory to catch-up, and OpenAI's recent assertions around a focus on efficiency and the ‘end of the age of large models’ (for now) supports this. Nvidia’s new GH200 chip, recently announce and shipping in Q2 2024, with HBM3e, offering a “50% speed increase” and supporting models that can be up to “3.5x larger” can’t come soon enough.
Interconnects between servers also play a performance role and can limit large models. This is borne out by the fact that US export controls apply specifically to interconnect bandwidth and not to the speed of the chip itself. Limiting the interconnect performance of chips exported is intended to have a crippling effect on Chinese firms ability to train and run inference for larger models. Whilst it will slow things in the short term, it’s an area where necessity may drive invention.

Outside of Google’s TPUv4/5 infrastructure and tooling, training workloads have to date been easier to scale using the Nvidia stack and unique CUDA GPU programming framework. But Open AI and others have been developing an abstraction called Triton which in the future will support cross-platform chip usage and may challenge Nvidia's 'moat' levelling the playing field for other firms (and possibly also China although the ecosystem there too have skilled-up heavily in the use of CUDA).
D. Monetisation feedback loop
Morgan Stanley are suggesting that Nvidia is reaching a valuation peak with a 200% share price rally in the last year indicating the nearing limits of the AI bubble. This is probably the market anticipating the limits around Nvidia’s growth and the dynamics of limited chip supply and a market share that can only drop as high demand stimulates competitors.
It’s probable that in the next 18 months investors will become increasingly concerned about the compute constraints, and thus the return on investment in AI. This might dampen the current excessive 10x demand and in-turn dampen manufacturing and infrastructure investment, slowing the roll-out of future generations of compute. It will also increasingly push firms to focus on the inference needed for user monetisation which could have a dampening effect on new model innovation and large training runs and so-on. Post compute-crunch the compute levels will start to unlock huge returns, but there will be bumps in the road. This process will also free up-capacity for new ideas and give technical evolution a chance to select the strongest neuromorphic innovations.
E. Design feedback loop
Current AI chips were designed when the potential and specific challenges of the latest LLMs were not fully known. Whilst it exciting to see AI increasingly used to accelerate chip design - Nvidia used AI to design 13,000 circuits in the H100 - it will take several years for LLM design optimisations to make it into running infrastructure. The design of new highly specialised AI chips or ASICs is being explored, especially by the hyperscalers and Google in particular, but their benefits at scale remain unproven, and with demand surging right now, they won't be playing a big role in the short-term.
The AI compute mystery
With the supply of chips constrained for the reasons outlined above, the question arises as to how many do we have today, and when will we get more? Given Nvidia and other firms typically remain tight-lipped about sales numbers and shipment projections, this is a hard thing to quantify.
It is however possible to approximately estimate shipments from Nvidia's overall data centre hardware revenues, dominant share of the market (we can be certain they are not giving these things away for free), and analysts future revenue growth estimates. If we assume an approximate price for each unit as a proportion of the average multi-chip server, a 2-year launch to replacement cycle, 80-90% Nvidia market share and analysts’ estimated revenue growth in 2024, quarterly AI chip shipments look something like this (updated to include Nvidia’s latest Q2 earnings data):
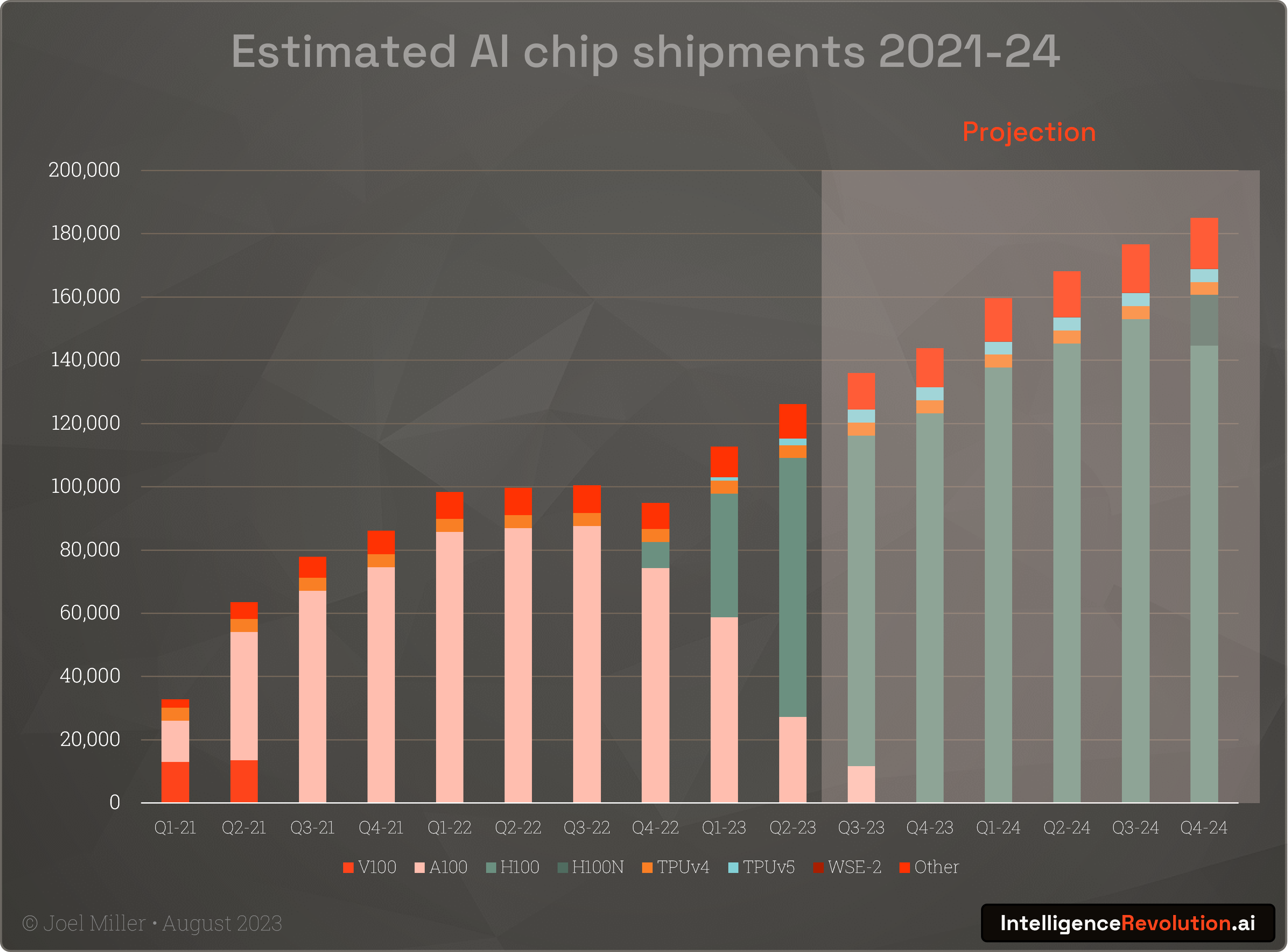
If we assume a 5+ year operational lifetime and calculate overall performance based on the typical BF16 floating point operations (FLOP) that are the optimal for current LLMs, we see that increasing performance and shipments will drive a significant uptick on available compute in the coming years (assuming the non-manufacturing constraints don't kick-in materially as shipments gradually grow). What is also clear is that assuming it can be shipped in the numbers anticipated (increasing to as many as 2 million in 2024), the new Nvidia H100 Hopper chip will provide the lions-share of momentum for the neuromorphic computing and intelligence revolution in the medium-term.
How much compute is enough?
Whilst there are some limits to the amount of compute we have today for AI, the multi-billion-dollar question is when will there be sufficient capacity to allow many firms to exploit this space, and to support the widespread global adoption and integration of new AI products and services?
One way to quantity demand is to estimate token based inferencing needs and the likely demand of training runs in the coming years. I have created a simple model using the following conservative assumptions:
Average model parameter and training token consumption growing gradually
2 operations and 6 operations for inference and training respectively, per token, remaining consistent into 2025, using 16-bit precision
User growth expanding in a linear fashion to 50% of the world's 1.1bn knowledge workers by 2025
Users generating at least 1 high-res image a week with their diffusion model of choice
A growing degree of token re-use with users using the same tokens in different models, experimenting with trial and error, and tree-of-thought prompting etc., all likely to inflate token demand
Up to 15 organisations (frontier labs, big-tech, new startups, and nation states) training 300bn+ parameter models in the next 18 months
Accurately estimating token demand is clearly impossible, but analysing based on rational current and future scenarios helps to put the compute situation in perspective:

Note that asking Bard, GPT-4, Claude 2, and using Perplexity.ai from some retrieval-augmented inference, yielded a range between 30,000 and 110,000 tokens per knowledge worker per day. It was interesting that Bard, despite repeated prompting, refused to provide a number, and was clearly adamant that this was a futile endeavour. A person typically speaks, reads, writes, and thinks around 100,000 words a day, so this total is not hard to imagine being a reasonable order of magnitude for an intensively augmented knowledge worker.
When we combine these modest chatbot-centric token demand numbers, plus conservative assumptions, and projected compute availability we see that the crunch is likely to continue perhaps until at least mid-2024:
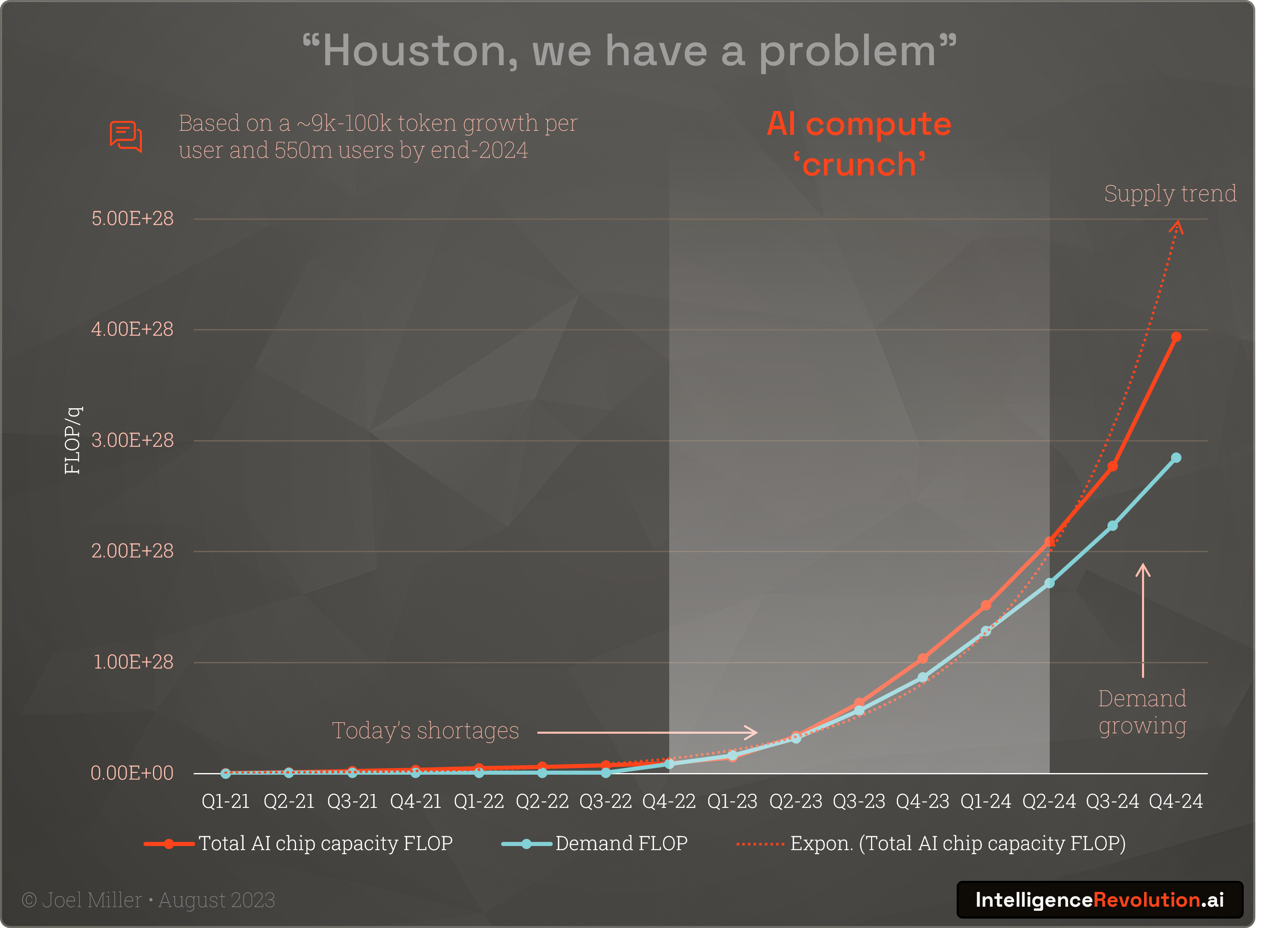
It can be argued that inference efficiency, increasing use of sparse models where not all parameters are activated such as GPT-4, and other strategies will help with compute demands at larger model sizes. It could also be argued that token demands from many more market entrants, innovation in autonomous AI, and a wide range of consumer products could be 10x or 100x higher.
Whilst the intelligence revolution is here, is also clear that there is no medium-term headroom for widespread innovation or human job replacement with current compute limits and large complex LLMs.
Smaller models and efficiency innovations such as quantisation, flash attention, pruning, batch optimisation, distillation, shogtongue, and many other tricks will be the name of the game in 2023 and 2024.
A steam engine in everyone's smartphone
As discussed here, iron forges led to the giant static steam engines of the early industrial revolution. Subsequently the brilliance of inventors such as James Watt made them much more efficient, freeing up industrial productivity from the physical constraints of geography and paving the way for steam locomotives connecting every town and village. In the next few years AI innovation will be needed, and will be encouraged, to take LLMs from high-end data centres to the hyperscalers standard hardware, and ultimately to the hundreds of billions of 'edge' chips in laptops and smartphones.
But as with most technological revolutions, Amara’s law will apply. Intensive hype is already encouraging many to overestimate the short-term impact of advances in LLMs and other neuromorphic computing innovations. I predict that in late 2024 when we're being told that the various opportunities and risks from AI were overstated, radically more powerful compute infrastructure and new chips will surge into data centres, and combine with disruptive new innovations born of several years of heavy capital investment, corporate and US-China competition, and extreme compute scarcity, to deliver AGI:
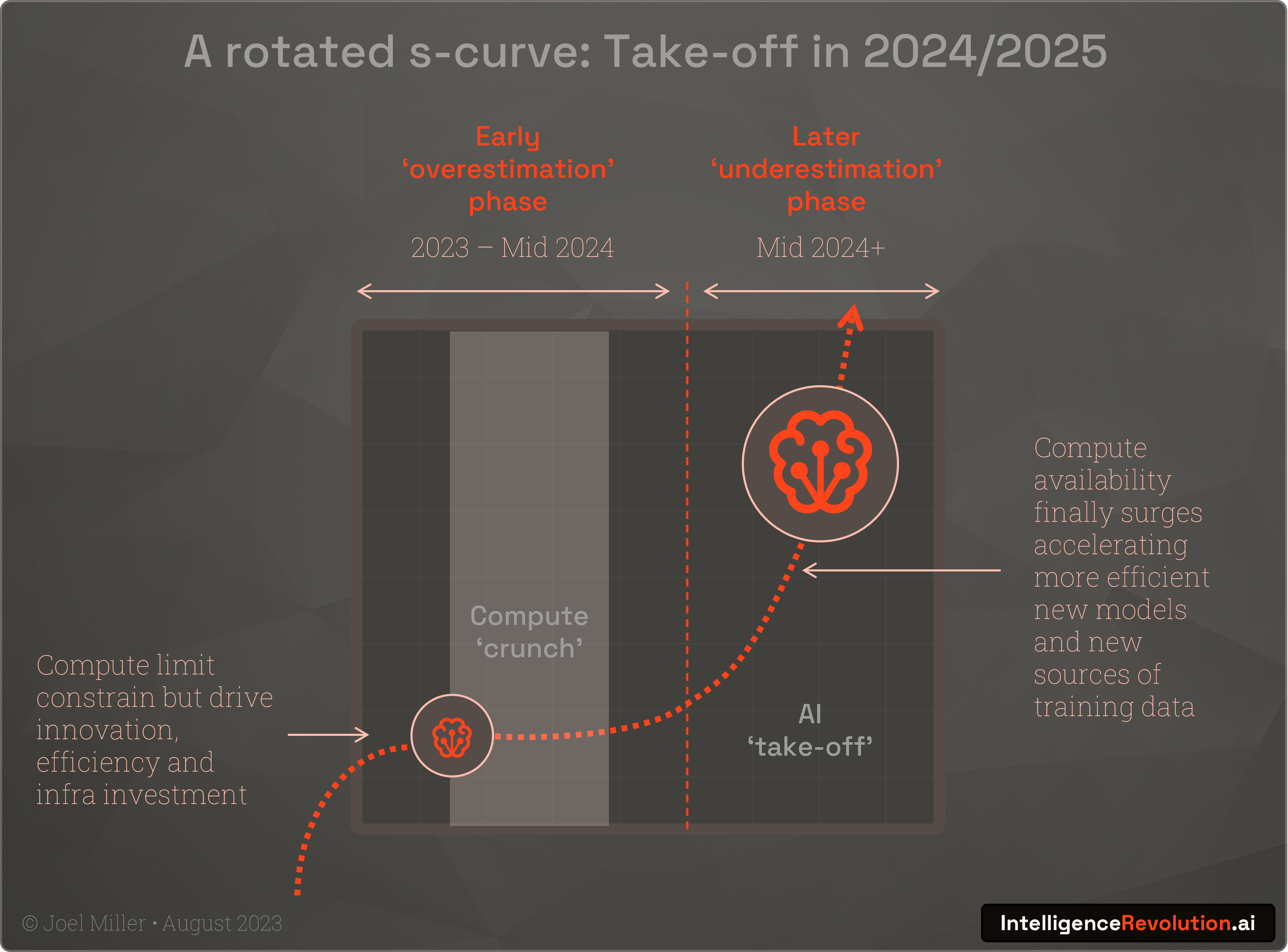
“Over the course of the next 10 years, I hope through new chips, new interconnects, new systems, new operating systems, new distributed computing algorithms and new AI algorithms and working with developers coming up with new models, I believe we're going to accelerate AI by another million times.”
Jensen Huang, Nvidia CEO (Feb 2023)
Even if Moore's law holds broadly true, current architecture AI chips will be at least 30x more powerful by the end of the decade. Beyond today’s architectures, multiple new innovations will also appear such as photonic chips and interconnects.
Given what has been possible with the computation of yesterday and today, we must use our 12-month ‘crunch’ window of opportunity to prepare. High stakes, high pressure technological, commercial, and geo-political competition is heating-up and the output can only be greater disruption to the intelligence landscape.
Subscribe to IntelligenceRevolution.ai to learn about a systems thinking approach to deploying powerful, efficient, and safe intelligent systems.